مقاله حاضر یک ساختار و چارچوب جدیدی را برای تحلیل حریم خصوصی داده فراهم میکند. چارچوب معرفی شده امکان انتشار پاسخ پرسوجوها از پایگاه داده را با اضافه کردن نویز مبتنی بر نمونه فراهم کرده است. به عبارتی دیگر، مقدار نویز اضافه شده نه تنها مبتنی بر نوع تابع پرس و جو، بلکه براساس خود پایگاه داده نیز مشخص شده و قابل تغییر است.
مفهوم دیگری که در این مقاله به آن پرداخته شده است، smooth sensitivity تابع پرس و جو بر روی پایگاه داده بوده است. منظور از smooth (ملایم) این است که نویز نباید تغییرات سریعی برای هر همسایگی ورودی خود تجربه کند. برای پیاده سازی چارچوب معرفی شده، حتما میبایست در ابتدا میزان این حساسیت و یا تخمینی از آن محاسبه شود. نحوه محاسبه این حساسیت برای توابع متعددی از جمله تابع محاسبه مقدار متوسط و نیز تابع محاسبه هزینه minimum spanning tree ارائه شده است. همچنین روشی برای محاسبه میزان حساسیت اشاره شده برای هر تابعی(بلک باکس) مبتنی بر نمونهگیری معرفی شده و بر روی دو تابع k-SED و مدل آمیخته گوسی در خوشه بندی پیاده شده است.
چارچوب معرفی شده در این مقاله با عنوان Sample and Aggregate معرفی شده است. این چارچوب بدین صورت است که در ابتدا تابع پرس و جو (f) با یک تابع پرس و جوی دیگری (f`) که دارای حساسیت ملایم پایین و به صورت بهینه قابل محاسبه باشد، جایگزین میشود و سپس چارچوب حساسیت ملایم معرفی شده اعمال خواهد شد.
به عنوان مرحله اول از پیادهسازی چارچوب پیشنهادی، پایگاه داده x را به m پایگاه داده کوچکتر تقسیم شده به صورتی که هریک از این بخشها به صورت رندم و با اندازه n/m از مجموعه nتایی پایگاه داده انتخاب میشوند.
در مرحله دوم، تابع f روی هریک از پایگاه دادههای کوچک اعمال شده و خروجیهای Z1 تا Zm در خروجی به دست میآید.
در نهایت تابعی تجمیعی با نام center of attention که در این مقاله معرفی شده است، بر روی خروجیهای به دست آمده در مرحله پیشین اعمال میشود.
در نهایت نویز کالیبره شده مبتنی بر حساسیت ملایم در خروجی به دست آمده اعمال خواهد شد. تصویر زیر نمایش دهنده مراحل پیادهسازی این چارچوب است.
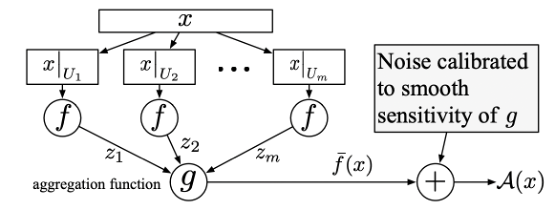
در واقع ایده اصلی این چارچوب این است که تغییر یک نقطه از پایگاه داده اصلی، تعداد بسیاری کمی از پایگاه دادههای تولید شده را تغییر داده و در نتیجه خروجیهای کمتری ناشی از اعمال تابع پرس و جو تغییر میکند.
پیشنهاد ارائه شده در این مقاله از این منظر که میزان نویز اضافه شده را نه تنها تابعی از پرس و جو، بلکه تابعی از خود پایگاه داده میداند با روشهای پیشین از جمله حریم خصوصی تفاضلی پیشنهادی توسط Dwork در سال ۲۰۰۶، متفاوت است. این ویژگی سبب شده است که امکان اعمال آن بر روی رنج وسیعتری از توابع پرس و جو و دادهها وجود داشته باشد.
Kobbi Nissim, Sofya Raskhodnikova, and Adam Smith. 2007. Smooth sensitivity and sampling in private data analysis. In Proceedings of the thirty-ninth annual ACM symposium on Theory of computing (STOC ’07). Association for Computing Machinery, New York, NY, USA, 75–84.