در این مقاله به بررسی سازوکار «انتشار دادههای خصوصی با ابعاد بالا» میپردازیم که به اختصار آن را DP2-Pub مینامیم و از دو مرحلهی خوشهبندی ویژگیها با استفاده از Markov-blanket و پس از تصادفی سازی (PRAM) ثابت تشکیل شده است.
انتشار دادههای با ابعاد بالا یک مساله چالش برانگیز است. چرا که با افزایش ابعاد، پیچیدگی و هزینه پردازش و تحلیل دادهها به طور صعودی افزایش مییابد.
روشهای قبلی
یکی از روشهای معروف، PrivBayes است که با توجه به مجموعهداده D یک شبکه بیزی N ساخته میشود که:
- یک مدل مختصر از همبستگیهای بین ویژگیهای موجود در D میسازد.
- این امکان را میدهد تا بهجای کار مستقیم با توزیع کل مجموعه داده، از مجموعه کوچکتری از نمایشهای با ابعاد پایین(P) برای ایجاد تقریبی از توزیع داده اصلی استفاده شود.
PrivBayes نوفه را به P تزریق میکند تا حریم خصوصی تفاضلی را فراهم کند و ازمقدار نوفهدار و شبکه بیزی ایجاد شده، برای ایجاد تقریبی از توزیع دادهها در D استفاده میکند. در نهایت، PrivBayes از توزیع تقریبی تاپلها، نمونه برداری میکند تا یک مجموعه داده مصنوعی بسازد و سپس دادههای مصنوعی را منتشر میکند.
مقایسه PRIVBAYES با راهکار پیشنهادی این مقاله
- از آنجایی که ابعاد متفاوت، دارای حساسیت متفاوت هستند ابتدا دادهها را خوشه بندی کرده و سپس متناسب با حساسیت هر خوشه، بودجه حریم خصوصی مناسب تخصیص مییابد.
- ایجاد توزیعهای شرطی نوفهدار از شبکه بیزی، سودمندی داده را کاهش میدهد به همین دلیل از سازوکار PRAM ثابت برای نوفهدار کردن خوشهها استفاده میشود و با اینکار سودمندی داده بهبود مییابد.
پیادهسازی DP2-Pub با یک سرور قابل اعتماد
از دو مرحله خوشهبندی و تصادفیسازی داده تشکیل شده است. بودجه حریم خصوصی به دو بخش تقسیم شده که یکی به مرحله اول و دیگری به مرحله دوم اختصاص مییابد.
مرحله اول: ابتدا به کمک شبکه بیزی، گراف ارتباط بین ویژگیها رسم میشود.
شبکه بیزی: یک گراف جهتدار فاقد دور است که گرههای آن، ویژگیها و یالهای آن، وابستگی مستقیم بین گرهها است.
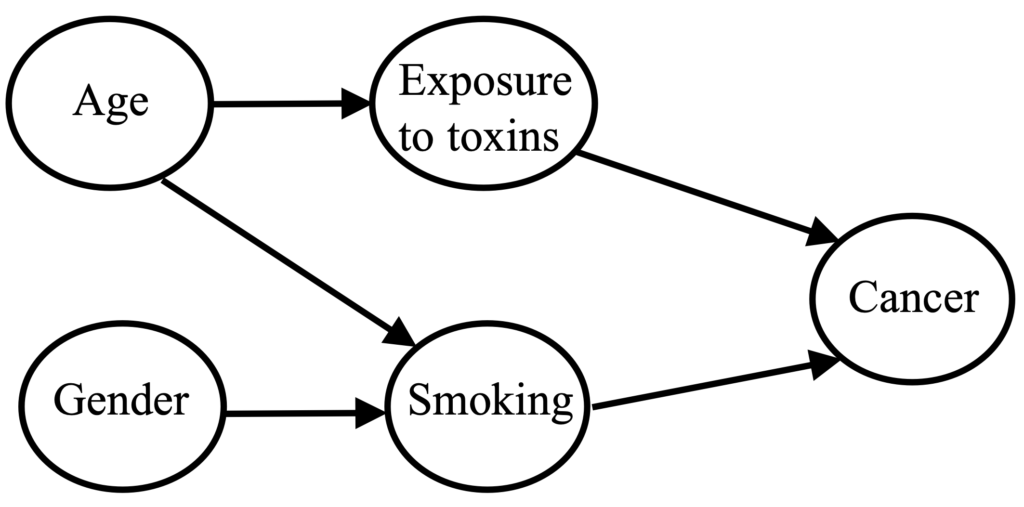

الگوریتم زیر، شبکه بیزی را با حفظ حریم خصوصی تفاضلی ایجاد میکند:

و سپس به کمک (MB)Markov blankets، عملیات خوشهبندی انجام میگیرد:
MB(x) = Pa(x)⋃Ch(x)⋃{Pa(y)∣y ∈ Ch(x)}

مرحله دوم: در این مرحله PRAM بر روی هر خوشه اعمال میشود.
PRAM یک روش آشفتهسازی برای حفاظت از افشای متغیرهای طبقهبندی است که مشابه RR است با این تفاوت که به طور تصادفی هر رکورد را با استفاده از احتمالات از پیش تعیین شده نوفهدار میکند.در صورت ثابت بودن PRAM، اطلاعات آماری کمی از دست رفته و درنتیجه سودمندی داده افزایش مییابد.
از آنجایی که یکی از تفاوتهای بارز راهکار پیشنهادی این مقاله با سایر روشهای موجود، تخصیص بودجه حریم خصوصی مناسب به هر خوشه است، ابتدا راهکار موردنیاز برای تعیین مقدار بودجه حریم خصوصیای که باید به هر خوشه اختصاص یابد را معرفی کرده و سپس روش PRAM توضیح داده میشود. فرمول زیر درجه اهمیت هر خوشه که با CIF نمایش داده میشود را مشخص میکند:
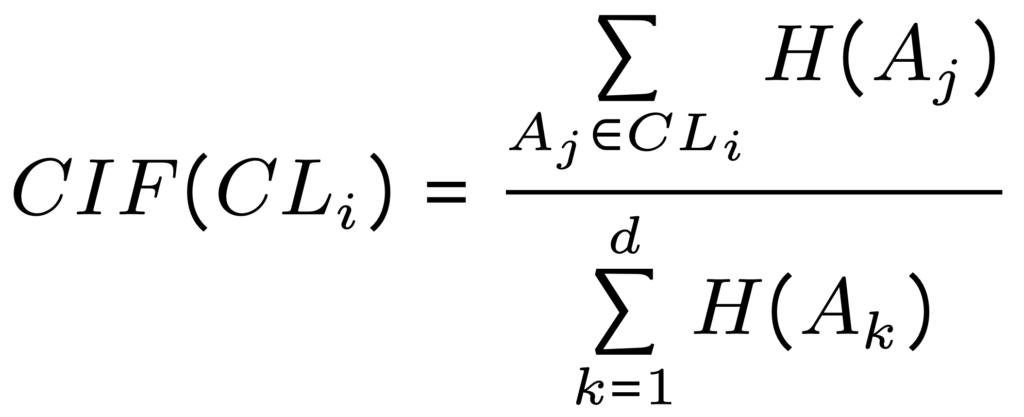
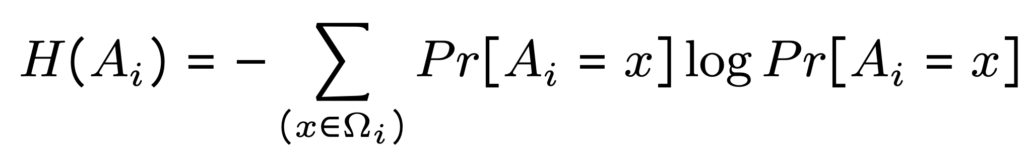
و سپس ضریب بودجه حریم خصوصی (PBC) برای هر خوشه به صورت زیر تعریف میشود:
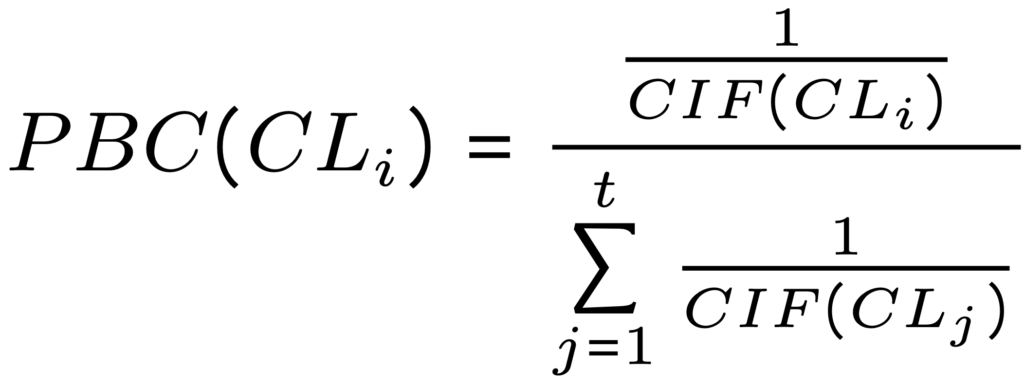
بودجه حریم خصوصیای که به مرحله دوم اختصاص مییابد را با ε2 نمایش میدهند. بنابراین بودجه حریم خصوصیای که به هر خوشه اختصاص مییابد برابر PBC(CLi). ε2 است.
در تصویر زیر مراحل تصادفیسازی مضاعف نشان داده شده:
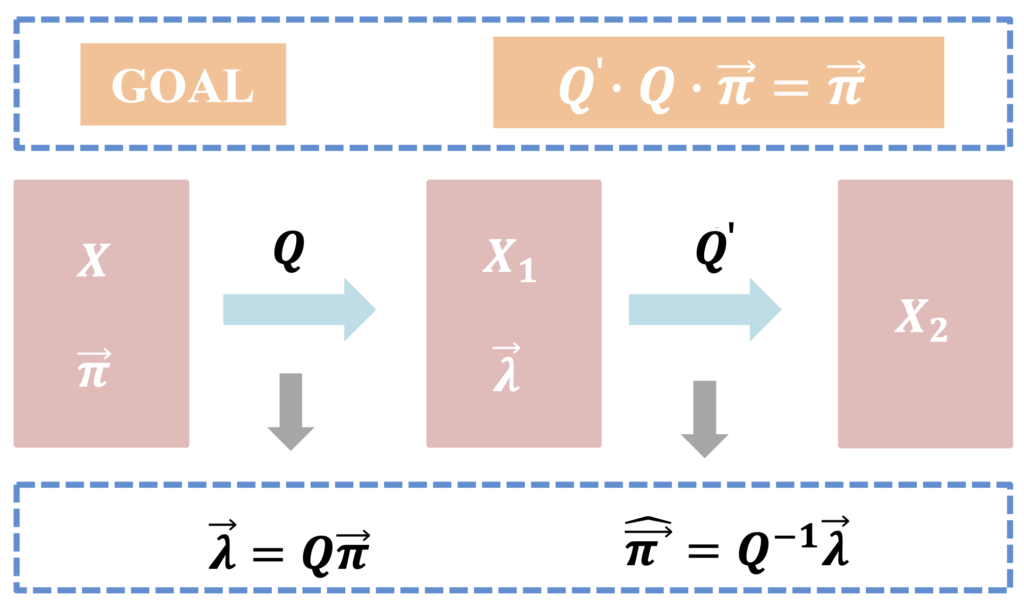
و در ادامه هر یک از متغیرهای به کار رفته شده توضیح داده میشود:
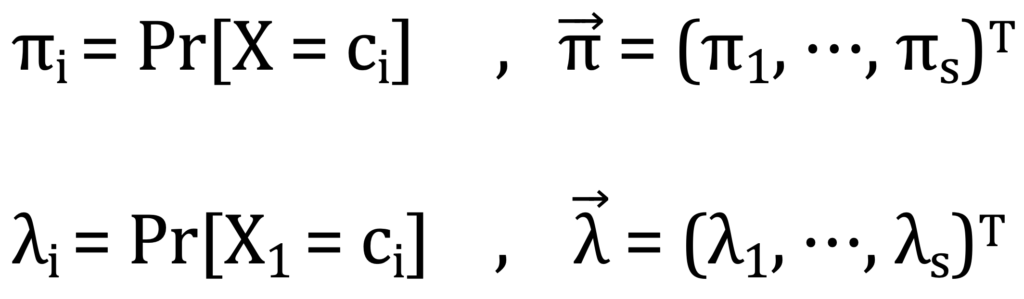
(Q=(qij ماتریس احتمال تغییر برای آشفتهسازی اول که به صورت زیر است:

‘Q ماتریس احتمال تغییر برای آشفتهسازی دوم است.
و از آنجایی که یک خوشه ویژگی ممکن است شامل بیش از یک متغیر ویژگی دو ارزشی یا چند ارزشی باشد که به شدت همبستگی دارند، میتوان همه این متغیرها را به عنوان یک متغیر ترکیبی در نظر گرفت. به عنوان مثال، برای دو متغیر طبقهبندی X با دستههای r و Y با دستههای s، ابتدا میتوانیم ماتریس احتمال انتقال PRAM ثابت X و Y را محاسبه کرد که به ترتیب با (fij)=F و (eij)=E نشان داده میشود. , سپس ترکیبی از X و Y را ایجاد کرد:
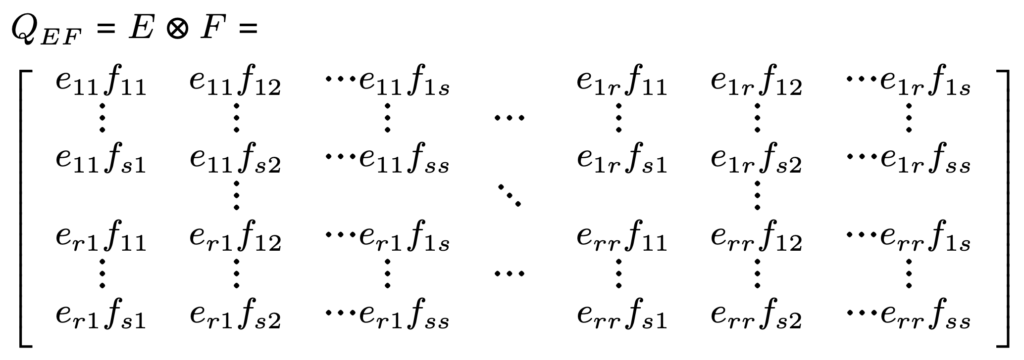
در اینجا بدلیل اینکه خوشه iام ممکن است بیش از یک متغیر ویژگی داشته باشد، بودجه حریم خصوصی ای که به هر خوشه اختصاص می یابد با فرمول زیر محاسبه میشود:
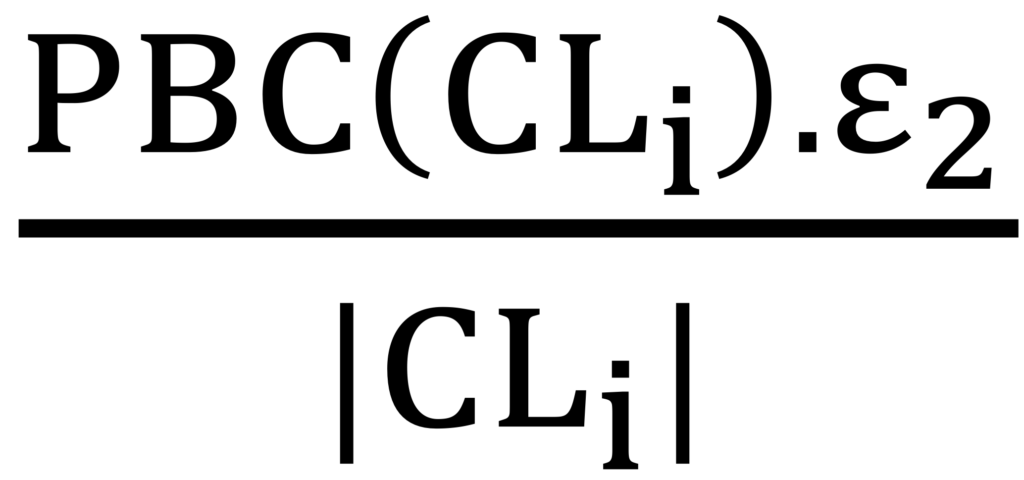
در نتیجه، مرحله اول که متشکل از شبکه بیزی و خوشهبندی بود، حریم خصوصی تفاضلی با عامل ε1 را حفظ میکند. چراکه شبکه بیزی حریم خصوصی تفاضلی را حفظ کرده و خوشهبندی آن، اطلاعات بیشتری را فاش نمیکند. و در مرحله دوم که عملیات تصادفیسازی بر روی نتیجه مرحله اول که حافظ حریم خصوصی تفاضلی است، صورت میگیرد، اطلاعات بیشتری را فاش نمیکند. بنابراین نتیجه این مرحله هم حافظ حریم خصوصی تفاضلی با عامل ε2 است. بنابراین DP2-Pub، حافظ حریم خصوصی تفاضلی با عامل ε1+ ε2 است.
پیادهسازی DP2-Pub با یک سرور نیمه صادق
مراحل پیادهسازی:
- حفظ حریم خصوصی دادههای محلی که حریم خصوصی تفاضلی محلی را برآورده میکند. اینکار با استفاده از مکانیسم «پاسخ تصادفی» به صورت زیرانجام میگیرد:
- اگر دادهها two-valued باشند:

-
- اگر دادهها multi-valued باشند:
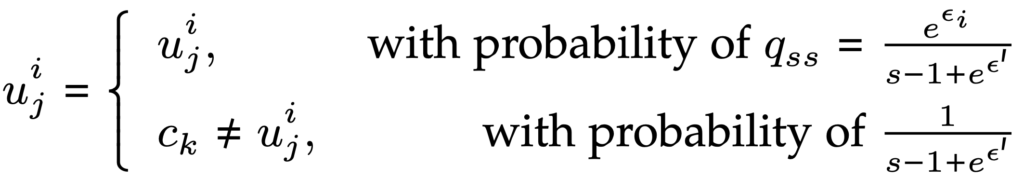
- خوشهبندی: این روش مشابه algorithm1 است با این تفاوت که در خط ۶ این الگوریتم به جای (Ai,Πi)، بزرگترین 1(I(A, Π قرار داده میشود. چرا که در مرحله قبل عملیات حفظ حریم خصوصی انجام گرفته و دیگر نیازی به فراهم کردن حفظ حریم خصوصی تفاضلی دوباره نیست. و برای بهبود دقت، خط ۵ مربوط به algorithm2 با عبارت ”Select the attribute x with the maximal entropy in S“ جایگزین میشود.
- تصادفیسازی با استفاده از PRAM ثابت
بنابراین DP2-Pub با یک سرور نیمه صادق، حریم خصوصی تفاضلی محلی را با عامل ε برآورده میکند.
نتایج
- از آنجایی که در روش DP2-Pub از شبکه بیزی فقط برای یادگیری همبستگی بین ویژگیها استفاده میشود، سودمندی داده نسبت به روش PrivBayes افزایش مییابد.
- روش DPPro فقط به حفظ فواصل بین جفت نقاط داده اهمیت میدهد و به ویژگیهای منحصر به فرد دادهها توجه نمیکند. بنابراین ممکن است منجر به کاهش سودمندی شود، به خصوص زمانی که همبستگی بین ویژگیهای مختلف زیاد باشد.
- فاصله تغییرات بین دادههای اصلی و دادههای آشفته با افزایش ε کاهش مییابد. بدیهی است که وقتی ε بزرگتر باشد، نوفه کمتری مورد نیاز است و سودمندی داده بیشتر است.
- دقت طبقهبندی روش DP2-Pub بهتر از روشهای PrivBayes و DPPro است. چرا که روش DP2-Pub می تواند با حفظ بهتر همبستگیها بین ویژگیها و دقت بالاتر توزیعهای مشترک، به سودمندی دادههای بالاتری دست پیدا کند.
- (۰,۰)I نشان دهنده میزان وابستگی بین دو مقدار است. ↩︎
Honglu Jiang et al. “DP2-Pub: Differentially Private High-Dimensional Data Publication with Invariant Post Randomization”. In: IEEE Transactions on Knowledge and Data Engineering (2023).