برای جمعآوری دادهها، چندین طرح حریم خصوصی تفاضلی محلی(LDP) وجود دارد که حریم خصوصی قویای را برای افراد تضمین کرده و در عین حال سودمندی مناسبی را نیز فراهم میکنند. با این حال، هنگامی که جمعآوری مداوم دادهها برای ارائه خدمات بیدرنگی نظیر پیشبینی ترافیک جادهای صورت میگیرد، سودمندی داده به صورت صعودی افزایش مییابد.
روشهای قبلی
راهحلهای LDP موجود برای جمعآوری مداوم دادهها، به دو دسته زیر تقسیم میشوند:
- رویکردهای مبتنی بر حافظه
- روش RAPPOR برای تخمین فراوانی مقادیر گسسته پیشنهاد شده است که از تکنیک دخیرهسازی استفاده میکند. اما ذخیره کردن ممکن است موجب نشت حریم خصوصی در نقاطی از داده که در طول زمان تغییر میکنند، شود و درنتیجه موجب نقض حریم خصوصی میشود.
- بنابراین dBitFlipPM پیشنهاد شده است که تکنیک ذخیرهسازی را بهبود میبخشد اما همچنان امکان نشت اطلاعات نیز وجود دارد.
- رویکردهای مبتنی بر تغییر دادهها
- 18-.M.J پیشنهاد شده است که نیاز به دسترسی به دادههای واقعی کاربر دارد، بنابراین بودجه حریم خصوصی باید تقسیم شود و تنها نصف آن برای تخمین استفاده میشود، که به سودمندی داده آسیب میرساند.
- U’.E.-19 برای مدیریت تغییرات دادهها در طول تخمین فراوانی مداوم پیشنهاد شده است. در این روش فرض میشود که دادهها حداکثر C بار تغییر میکنند. و هر کاربر یکی از تغییرات دادههای C خود را انتخاب کرده و آن را به عنوان بخشی از تجزیه و تحلیل گزراش میکند. با این حال، فرض درنظر گرفته شده ممکن است به اندازه کافی در برنامههای کاربردی دنیای واقعی عملی نباشد، زیرا برای برآورده کردن کامل این فرض، C باید روی بیشترین تعداد ممکن تغییرات تنظیم شود، که به دلیل فرآیند نمونهگیری سمت client، موجب کاهش سودمندی داده میشود.
یک ایده ساده برای فراهم کردن حریم خصوصی تفاضلی برای دادههای سری زمانی، تقسیم بودجه حریم خصوصی و اختصاص آن به هر دوره زمانی است که با افزایش تعداد دورههای زمانی، بودجههای حریم خصوصی اختصاص یافته به هرکدام نیز کاهش مییابد و دیگر این روش کارآمد نیست.
(Dynamic Difference Report Mechanism)DDRM
در DDRM به جای ذخیرهسازی و آشفتگی هر مقدار، تفاوت هر دو مقدار متوالی ثبت میشود که بر اساس آن difference tree برای ذخیره دادههای سری زمانی ساخته میشود و مقدار هر گره یکی از سه مقدار {1,0,1-} است.
قبل از شروع مراحل اصلی این الگوریتم نیاز است تا بودجه حریم خصوصی تقسیم شود و برای اینکار نیاز است تا پارامتر k مشخص شود.
نحوه تنظیم k:
دو نوع خطای زیر در محاسبه تخمین فراوانی وجود دارد:
- خطای نوفه که به دلیل نوفهدار کردن دادهها به وجود میآید و با errnt نشان داده میشود.
- خطای دستکاری که به دلیل تمام کردن بودجه حریم خصوصی توسط کاربران به وجود میآید و با errmt نشان داده میشود.
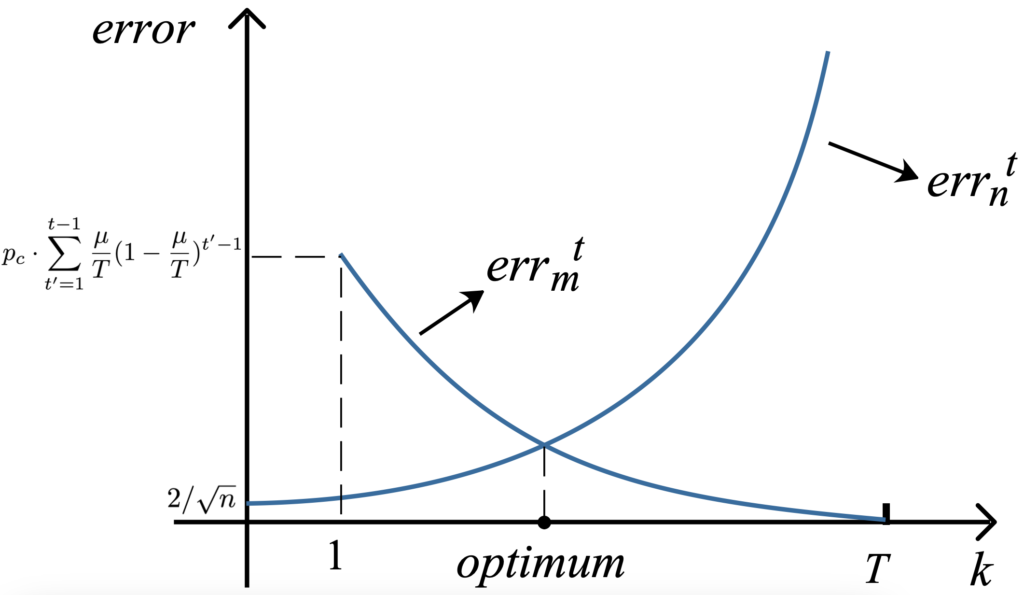
طبق نمودار بالا، برای kهای کوچک، errmt و برای kهای بزرگ، errnt بزرگ است و در هردو حالت سودمندی داده پایین است. بنابراین نیاز است تا به منظور کاهش این دو نوع خطا و افزایش دقت تخمین، یک k≤T) k) مناسب انتخاب شود.
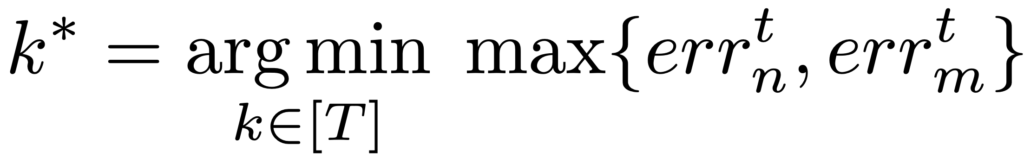
مراحل DDRM
- بهروزرسانی difference tree: در ابتدا کاربر cit = dit – dit-1 که 0 = di0 است را به ازای هر t محاسبه و آنها را به درخت اضافه میکند و درخت را به صورت محلی بهروزرسانی میکند. citها برگهای درخت را تشکیل میدهند درحالی که مقدار گرههای غیربرگ برابر است با حاصل جمع فرزند چپ و راست آن گره. برای مثال [1,1,1,0,0,0,1,1]=di به [1,0,0,1,0-,1,0,0]=ci تبدیل میشود.
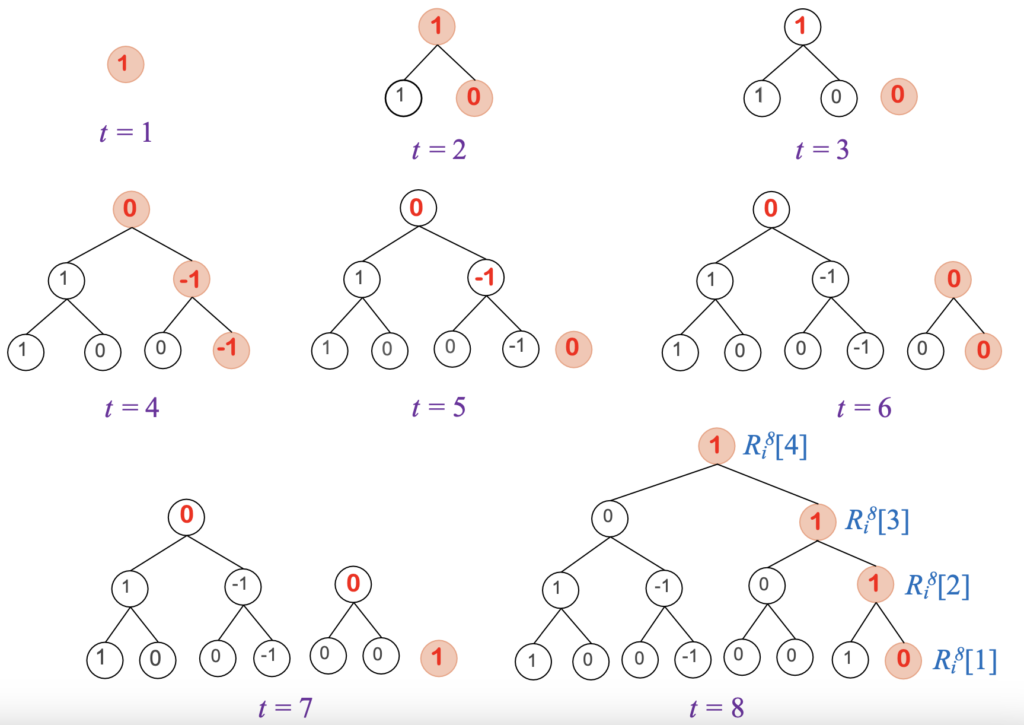
به منظور کاهش فضای ذخیرهسازی، فقط گرههای کلیدی که همان سمت راستترین گره در هر سطح هستند، ذخیره میشود.
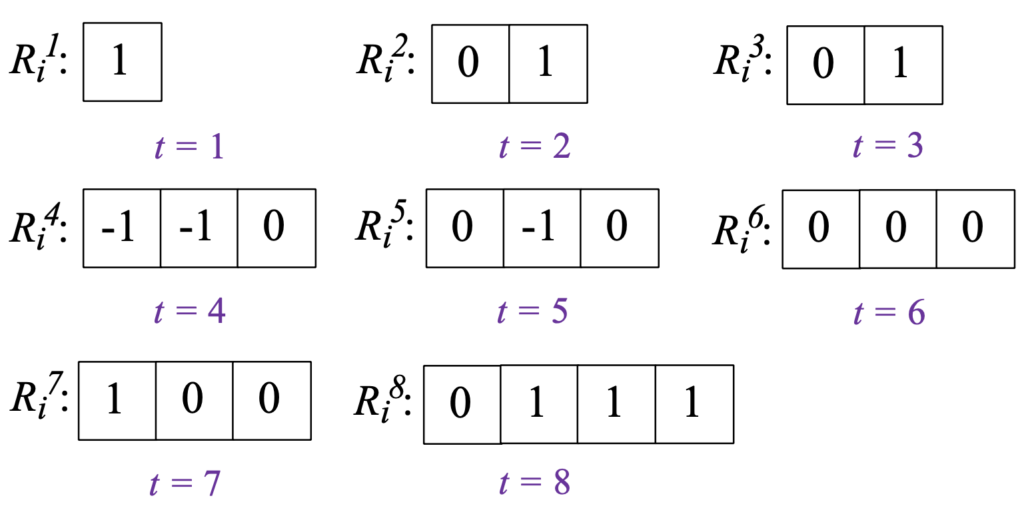
- انتخاب گره مناسب: در راهکار پیشنهادی، آخرین برگ و یا گرههای غیر برگی را که مقدار آنها با مقدار فعلی در ارتباط است به عنوان گره مناسب انتخاب میشود. برای مثال زمانی که 8=t است سه گره غیربرگ [2]𝑅i8[3],𝑅i8 و [4]𝑅i8 برای انتخاب وجود دارد که با انتخاب هر کدام، مقدار فراوانی به صورت زیر تخمین زده میشود:
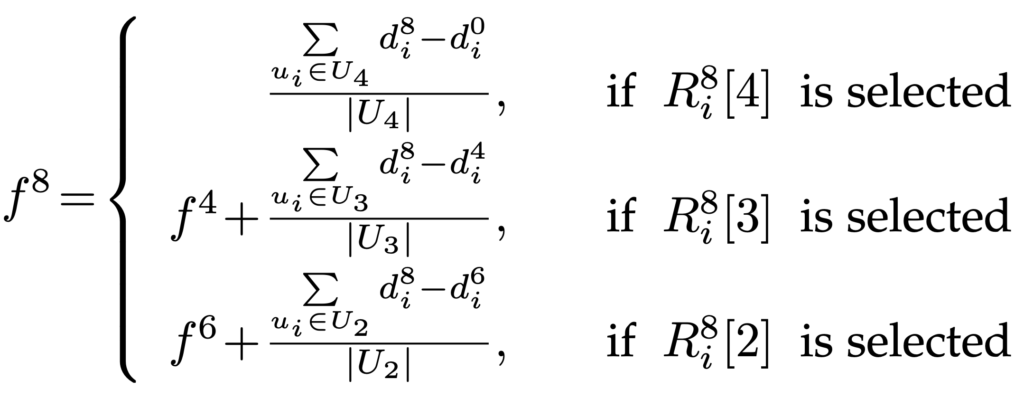
از آنجایی که تخمین فروانی f8 به تخمین فراوانی f4 و f6 وابسته است بنابراین خطای تخمین در طول زمان انباشته میشود که میتوان این خطا را با انتخاب بالاترین سطح گره از بین گرههای قابل انتخاب، کاهش داد. بنابراین، استراتژی انتخاب گره باید آخرین گره برگ یا گره غیربرگ مرتبط با مقدار فعلی با بالاترین سطح را انتخاب کند.
- عملیات آشفتهسازی: اگر v ∈ {-1 ,1} باشد:
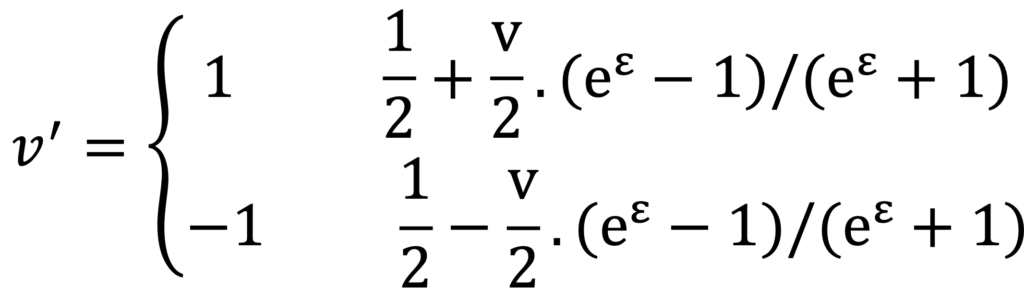
اگر 0=v باشد، با احتمال مساوی 0.5 و بدون نیاز به بودجه حریم خصوصی، به 1- یا 1 تبدیل میشود. بنابراین بودجه حریم خصوصی بیشتری را میتوان به مقدار 1 یا 1- اختصاص داد.
- تخمین فراوانی: در سمت جمعکننده ابتدا دادههای دریافتی را با فرمول زیر کالیبره1 میشود:
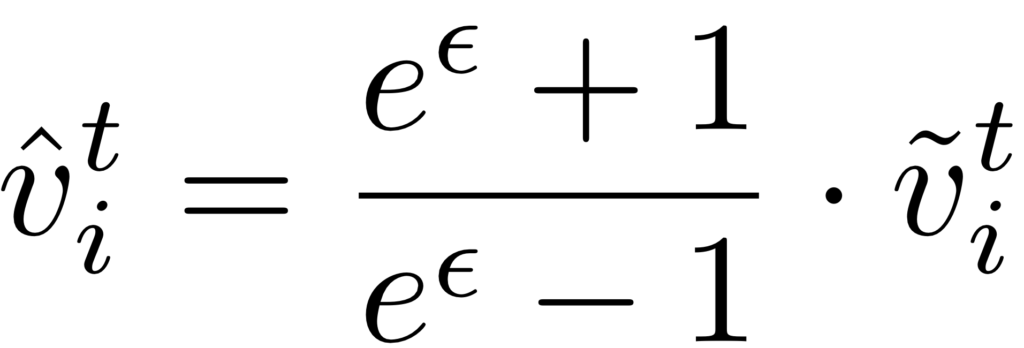
طبق استراتژی انتخاب گره، در زمانهای زوج، نصف کاربران مقدار برگ و نصف دیگر کاربران مقدار ریشه را گزارش میکنند. به همین دلیل، جمعکننده داده میتواند دو تخمین فراوانی از داده در t زوج محاسبه کند.
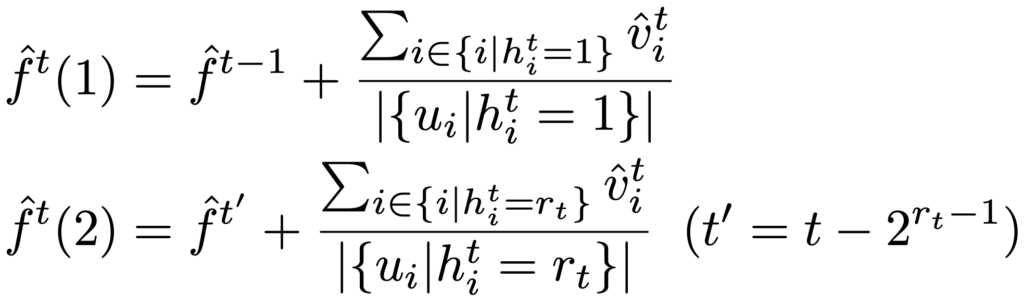
سپس جمعکننده تخمین فراوانی نهایی را به دست میآورد:
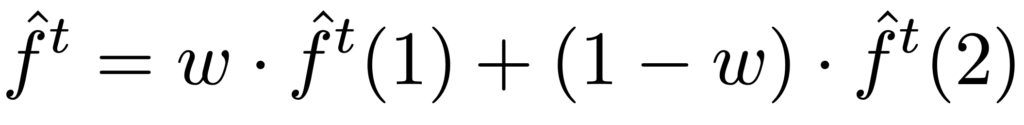
برای اینکه تخمین فراوانی نهایی بدست آمده بهینه باشد w به صورت زیر محاسبه میشود:
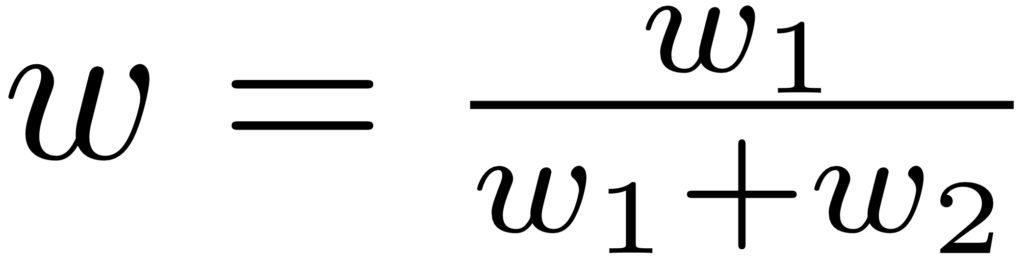
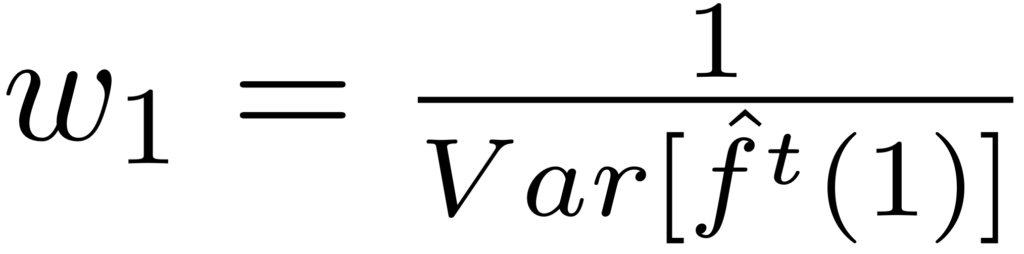
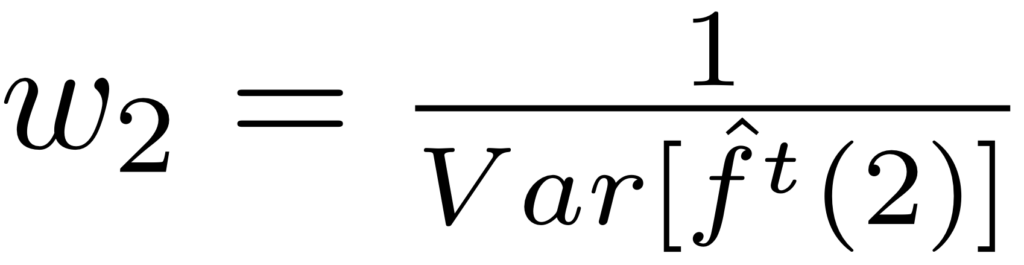
بنابراین داریم:
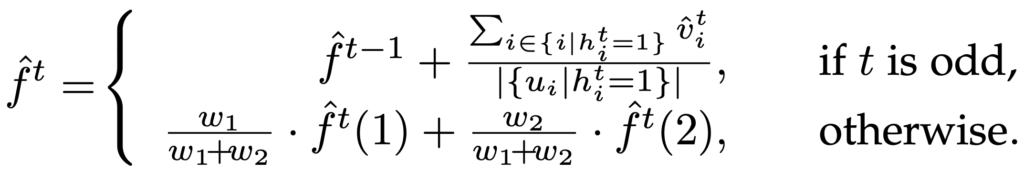
گسترش روش DDRM برای دادههای Multi-Valued:
برای اینکار میتوانیم هر مقدار v را به یک بردار باینری M بیتی V رمزگذاری کنیم، که در آن فقط بیت vام از V برابر 1 است و بقیه بیتها 0 هستند. برای هر بیت از بردار رمزگذاری شده، هر کاربر میتواند به صورت محلی difference trees را مدیریت کرده و سپس از DDRM برای تخمین فراوانی آن استفاده کند. با این حال، این روش مشکلاتی را نیز ایجاد میکند. اولا ً، هزینه ذخیرهسازی محلی هر کاربر و هزینه ارتباط بین کاربران و جمعآورنده دادهها متناسب با M خواهد بود. دوما utility بدست آمده از پروتکل آشفتهسازی دیگر به راحتی بدست نمیآید. برای حل هر دو مشکل، پیشنهاد میشود تا کاربران به گروههایی تقسیم شده و کاربران هر گروه فقط زیر مجموعهای از بیتها را گزارش کنند.
آزمایش:
برای مقایسه عملکرد الگوریتم DDRM با الگوریتمهای U ́.E.-19 ،M.J.-18 ،dBitFlipPM ،RAPPOR وToPL، چهار آزمایش زیر انجام گرفته:
- آزمایش اول: این آزمایش بر روی دادههای باینری انجام میگیرد. و نتایج آن به شرح زیر است:
- dBitFlipPM دارای کمترین loss است درحالی که DDRM دومین است.
- RAPPOR و ToPL دارای عملکردی مشابه هستند.
- M.J.-18 فقط از نیمی از بودجه حریم خصوصی برای تخمین فراوانی استفاده میکند که موجب افزایش نوفه و کاهش دقت میشود.
- در 19-.U’.E، دادههای سری زمانی حداکثر C بار در دوره زمانی T تغییر میکنند و هر کاربر به طور تصادفی یک مقدار c را از {C ,…,1} انتخاب میکند و c-امین تغییر را با تمام بودجه حفظ حریم خصوصی برای گزارش آشفته میکند. اگر C، مقدار بزرگی درنظر گرفته شود، موجب خطای نمونهگیری بزرگی میشود. اگر C مقدار معقول کوچکی درنظر گرفته شود، موجب تخمین مغرضانه میشود و دقت تخمین را کاهش میدهد.
- هرچند که dBitFlipPM دارای بهترین عملکرد است اما بدلیل داشتن ویژگی ذخیرهسازی، دارای یک سری محدودیتها است که ممکن است نقاط تغییر داده را آشکار کند. و با افزایش بودجه حربم خصوصی احتمال وقوع این حمله بیشتر میشود. درحالی که الگوریتم DDRM فاقد چنین حملهای است.
- آزمایش دوم: این آزمایش بر روی دادههای multi-valued انجام میگیرد. و نتایج آن به شرح زیر است:
- DDRM دارای بهترین عملکرد برای بودجه حریم خصوصی کوچک (ε < 3) است اما با افزایش بودجه حریم خصوصی، دقت DDRM به دقت dBitFlipPM نزدیک میشود.
- M.J.-18 بدلیل استفاده از نیمی از بودجه حریم خصوصی برای محاسبه تخمین فراوانی و همچنین بدلیل پیادهسازی آن همراه با Succinct Histogram که مکانیزمی پایینتر از RAPPOR است، دارای بدترین عملکرد است.
- اثربخشی کم RAPPOR و dBitFlipPM برای ε کوچک عمدتا به دلیل تقسیم بودجه حریم خصوصی بر روی دادههای چند ارزشی است.
- دقت dBitFlipPM با افزایش d، افزایش مییابد اما افشای نقاط تغییر دادهها نیز بیشتر میشود.
- آزمایش سوم: این آزمایش برای بررسی تاثیر پارامتر k بر روی DDRM است. و نتایج آن به شرح زیر است:
- با در نظر گرفتن kها و εهای متفاوت، به این نتیجه میرسیم که انتخاب kی بهینه که روش محاسبه آن قبلا توضیح داده شده است، بهترین انتخاب است.
- با توجه به یک بودجه حریم خصوصی خاص در همان مجموعه داده، T(دوره زمانی) بزرگتر تمایل به انتخاب k بزرگتری دارد، که نشان دهنده تأثیر قابل توجه خطای errmt بر دقت تخمین است.
- آزمایش چهارم: این آزمایش برای بررسی تاثیر نرخ تغییر داده بر روی DDRM است. و نتایج آن به شرح زیر است:
- تغییرات مکرر، تاثیر منفی بر دقت تخمین DDRM میگذارد.
- نوسانات کوتاه بر عملکرد DDRM تأثیر زیادی نمیگذارد.
- کالیبره به معنای تنظیم یا تصحیح مقادیر نوفهدار دریافتی از کاربران است تا آنها را دقیقتر و یا با یک مرجع یا استاندارد مورد نظر هماهنگ کند. ↩︎
Qiao Xue et al. “DDRM: A continual frequency estimation mechanism with local differential privacy”. In: IEEE Transactions on Knowledge and Data Engineering (2022)