دادههای با ابعاد بالا مانند دادههای مراقبتهای بهداشتی يا دادههای رفتاری كاربر، برای اهداف متفاوتی مورد استفاده قرار میگيرند و اغلب اين دادهها در اختيار كاربران مختلفی قرار دارند، گويی كه دادهها به صورت افقی بين چندين طرف تقسيم شده است. گردهم آمدن دوباره اين دادهها میتواند در تصميمگيریها كمکكننده باشد و در نتيجه خدمات بهتری نيز ارائه میشود. با اين حال، ممكن است مجموعهدادههای نگهداري شده توسط هر يک از افراد، حاوی اطلاعات حساسی باشد كه ادغام و به اشتراکگذاری نتايج میتواند تهديدات جدی را برای حريم خصوصی افراد ايجاد كند.
مساله
فرض کنید K بخش داریم که به صورت P1,P2,…PK نمایش داده میشوند و هر بخش دارای مجموعهداده Dk است و هر مجموعهداده دارای{X={X1,X2,…,Xd ویژگی است که میتواند عددی یا طبقهبندی باشد. با دادن kتا مجموعهداده و بودجه حریم خصوصی K ،εتا بخش تمایل دارند تا مجموعهداده ساختگی ’D را در حالی که حریم خصوصی تفاضلی با عامل ε را فراهم میکند، ایجاد کنند. در اینجا جمعکننده داده نیمه معتمد میباشد.
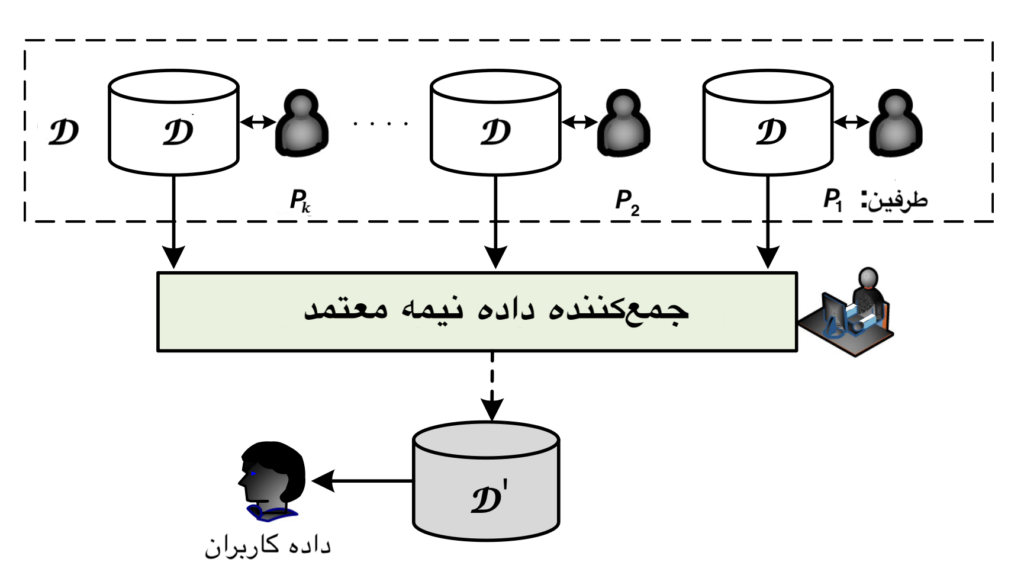
برای حل مساله موردنظر، راهکار DP-CCBN معرفی شده است که شامل مراحل زیر میباشد:
- یادگیری ساختار: در این مرحله، شبكه بيزی به همراه اعمال سازوكار DLPA تشكيل میشود. در اين مرحله ابتدا هر يک از طرفين در مجموعهداده محلي خود توزيعهای حاشيهای نوفهدار جفتهای ويژگی-والد كانديد را توليد كرده و آنها را برای جمعكننده داده ارسال میكنند. جمعكننده داده بعد از جمعآوری دادهها، اطلاعات متقابل بين ويژگیها و مجموعههای والدين كانديدشان را محاسبه كرده و درنهايت بهترين مجموعه والد را براساس اطلاعات متقابل انتخاب میكند.
- یادگیری پارامتر: در این مرحله، هر يک از طرفين توزيع حاشيهای تمامی جفت ويژگي-والد توليد شده از مرحله قبل را با استفاده از DLPA محاسبه كرده و به جمعكننده داده ارسال میكنند. جمعكننده داده نيز به كمک دادههای دريافتی، توزيع شرطي هر يک از ويژگیها را محاسبه میكند.
- تولید مجموعهداده ساختگی: در این مرحله، با استفاده از نتايج مراحل قبل و با بكارگيری سازوکار نمونهبرداری، يک مجموعهداده ساختگی توليد میشود.
از آنجایی که دو مرحله اول به دادههای اصلی دسترسی دارند، بودجه حریم خصوصی تفاضلی به دو قسمت مساوی تقسیم شده و به دو مرحله اول اختصاص مییابد.
وجود تعداد زيادی جفت ويژگی نامزد در مرحله يادگيری ساختار، منجر به سودمندی كم و هزينه ارتباطی بالای اين روش میشود. به همین دلیل راهکار DP-SUBN معرفی شده است و شامل مراحل زیر میباشد:
- شناسایی همبستگی: در این مرحله، ابتدا با استفاده از روش NOCD، نماهای فاقد همپوشانی ايجاد و سپس با اعمال سازوكار DLPA، توزيعهای حاشيهای نوفهدار از اين نماها ايجاد میشود. درنهايت براساس توزيعهای حاشيهای نوفهدار، حاشيههای دوطرفه محاسبه شده و اطلاعات متقابل هر يک از ويژگیها به منظور محاسبه همبستگیها، محاسبه میشود.
- مقداردهی اولیه ساختار شبکه بیزی: در این مرحله هر يک از كاربران، بخشي از ساختار شبكه بيزی را به همراه اعمال سازوكار نمايی مقداردهی اوليه میكنند.
- به روز رسانی شبکه بیزی: در این مرحله، ساختار شبكه بيزی به همراه اعمال سازوكار لاپلاس Kبار به روز رسانی شده و درنهايت شبكه بيزی نهايی ايجاد میشود.
- یادگیری پارامتر: مشابه مرحله «یادگیری پارامتر» راهکار «DP-CCBN» میباشد.
- تولید مجموعهداده ساختگی: مشابه مرحله «تولید مجموعهداده ساختگی» راهکار «DP-CCBN» میباشد.
به روزرسانی شبكه بيزی منجر میشود تا اين روش، فرآيند يادگيری دادههای با ابعاد بالا را به مراحل كوچكتری تجزيه كرده که درنهایت منجر به سودمندی بالای داده و هزينه ارتباطی كم میشود.
Xiang Cheng et al. “Multi-party high-dimensional data publishing under differential privacy”. In: IEEE Transactions on Knowledge and Data Engineering 32.8 (2019), pp. 1557–1571