حفظ حریم خصوصی دادهها هنگام انتشار آنها مساله مهمی است به همین دلیل از حریم خصوصی تفاضلی استفاده میشود. اما روشهای موجود، حریم خصوصی مناسبی را برای دادههای با ابعاد بالا فراهم نمیکنند چون مقدار نوفه اضافه شده بیش از حد معمول بوده و منجر به انتشار دادههایی میشود که برای تجزیه و تحلیل غیرقابل استفاده هستند. به همین دلیل در این مقاله روش جدیدی با نام PRIVBAYES معرفی میشود که حریم خصوصی تفاضلی دادههای با ابعاد بالا را فراهم میکند که:
- یک مدل مختصر از همبستگیهای بین ویژگیهای موجود در مجموعهداده D میسازد.
- این امکان را میدهد تا بهجای کار مستقیم با توزیع کل مجموعه داده، از مجموعه کوچکتری از نمایشهای با ابعاد پایین(P) برای ایجاد تقریبی از توزیع داده اصلی استفاده شود.
PrivBayes نوفه را به P تزریق میکند تا حریم خصوصی تفاضلی را فراهم کند و ازمقدار نوفهدار و شبکه بیزی ایجاد شده، برای ایجاد تقریبی از توزیع دادهها در D استفاده میکند. در نهایت، PrivBayes از توزیع تقریبی تاپلها، نمونه برداری میکند تا یک مجموعه داده جعلی بسازد و سپس دادههای جعلی را منتشر میکند.
مراحل PrivBayes:
- ساخت یک شبکه بیزی با درجه k با عامل حریم خصوصی ε/2.
شبکه بیزی: شبکه بیزی یک گراف فاقد دور جهتدار (DAG) است که هر ویژگی در A با یک گره نشان داده میشود و استقلال شرطی در بین ویژگیهای A با استفاده از یالهای جهتدار مدل میشود. برای هر دو ویژگی X,Y ∈ A، سه احتمال برای رابطه بین X و Y وجود دارد:
- رابطه بین X و Y از نوع مستقیم است. زمانی که میگوییم از X به Y به این معناست که Y وابسته به X است.
- استقلال شرطی ضعیف: بین X و Y مسیری وجود دارد اما یالی وجود ندارد.
- استقلال شرطی قوی: بین X و Y مسیری وجود ندارد.
یک شبکه بیزی به صورت جفت ویژگی-والد(AP) مشخص میشود و به صورت (X1 , Π1),…,(Xd , Πd) نمایش داده میشود. درجه یک شبکه بیزی برابر است با اندازه بزررگترین Πi.
- از یک الگوریتم حریم خصوصی تفاضلی با عامل (ε/2) برای تولید مجموعهای از توزیعهای شرطی نوفهدار استفاده میشود.

عملکرد این الگوریتم، با مثال زیر توضیح داده میشود:
فرض کنید یک شبکه بیزی با درجه ۲ با ۴ ویژگی {A,B,C,D} داریم که AP={(A,∅),(B,{A}),(C,{A,B}),(D,{A,C})}. با دادن این شبکه بیزی به عنوان ورودی دو توزیع مشترک نوفهدار Pr∗[A,B,C] و Pr∗[A,C,D] تولید میشود که بر اساس Pr∗[A,C,D] توزیع شرطی نوفهدار Pr∗[D | A,C] و بر اساس Pr∗[A,B,C] توزیعهای شرطی نوفهدار Pr∗[A], Pr∗[B | A] و Pr∗[C | A,B] تولید میشوند. که در نهایت خروجی این الگوریتم به صورت زیر است:
- با استفاده از شبکه بیزی و مقادیر نوفهدار، توزیع تقریبی از تاپلها ساخته میشود و سپس از توزیع تقریبی برای تولید مجموعه داده جعلی استفاده میشود.
اختلاف بین دو توزیع احتمال واقعی و تقریبی به صورت زیر محاسبه میشود:
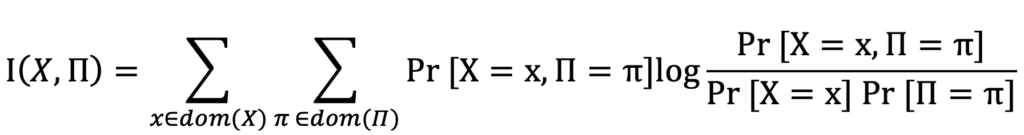
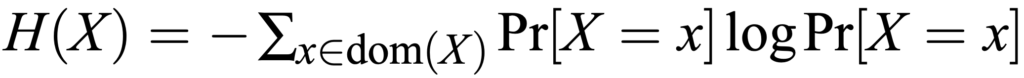
زمانی که k=1 است روش بهینهای پیشنهاد شده است که یال بعدیای که انتخاب میکند براساس بزرگترین اطلاعات متقابل است. با این حال، هنگامی که k>1 است، مشکل بهینهسازی ساختار درختی NP-hard میشود. برای حل این مساله الگوریتمهای اکتشافی مانند تپهنوردی، الگوریتمهای ژنتیک استفاده میشوند. اما استفاده از این الگوریتمها برای فراهم کردن حریم خصوصی تفاضلی، هزینه زیادی دارد. چون منجر به پرس و جوهای زیادی برای دادهها میشوند و درنتیجه منجر به حساسیت بالا و مقدار قابل توجهی نوفه در هنگام خصوصی کردن نتایج میشود که بر دقت کلی نتایج تأثیر منفی میگذارد. برای حل این چالش، یک الگوریتم حریصانه جدید پیشنهاد شده است که بین کاهش پرس و جوهای داده، به حداقل رساندن نوفه و بهبود دقت، تعادل ایجاد میکند.

در هر دور اجرا از این الگوریتم، ((X, Πیی از Ω انتخاب میشود که دو شرط زیر در آن برقرار باشد:
- Π|≤ k| باشد.
- شبکه بیزی ایجاد شده، یالی از Xi به Xj که j<i باشد، نداشته باشد. یعنی فاقد دور باشد.
اما الگوریتم ۲، حریم خصوصی تفاضلی را فراهم نمیکند و از آنجایی که تنها خط ۶ از این الگوریتم به مجموعهداده دسترسی دارد، کافی است خط ۶ از این الگوریتم را به گونهای تغییر دهیم تا حریم خصوصی تفاضلی را فراهم کند. به این منظور، روشهای زیر معرفی شدهاند:
- A First-Cut Solution
- در این روش برای فراهم کردن حریم خصوصی تفاضلی از سازوکار نمایی (exp(I(X,Π)/2Δ1 استفاده میشود و از اطلاعات متقابل I نیز به عنوان تابع امتیاز استفاده میشود.
- An Improved Solution
- روش قبلی، روشی ساده است اما ممکن است بهترین نتیجه را نداشته باشد. در این روش پیشنهاد میشود که به جای استفاده از I به عنوان تابع امتیاز در سازوکار نمایی، از تابع جدید F استفاده شود.
- حساسیت F کوچک است.
- اگر F(X,Π) بزرگ باشد، پس I(X,Π) نیز بزرگ است.
- روش قبلی، روشی ساده است اما ممکن است بهترین نتیجه را نداشته باشد. در این روش پیشنهاد میشود که به جای استفاده از I به عنوان تابع امتیاز در سازوکار نمایی، از تابع جدید F استفاده شود.
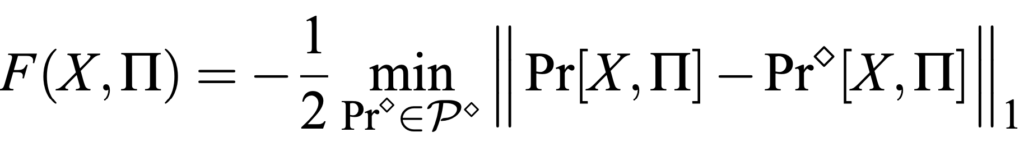
انتخاب K:
درصورت بزرگ بودن k، اطلاعات بیشتری از توزیع کامل نگه داشته میشود اما PRIVBAYES را مجبور میکند تا حریم خصوصی مجموعهای از توزیعهای حاشیهای با ابعاد بالا را در مرحله دوم فراهم کند، که به دلیل دامنههای بزرگشان در برابر نوفه بسیار آسیبپذیر هستند که موجب کاهش سودمندی آنها میشود، بهخصوص زمانی که بودجه حفظ حریم خصوصی ε کوچک است، که منجر به ایجاد پایگاه داده جعلی پر از اختلالات تصادفی میشود. مقدار k باید به گونهای انتخاب شود که بین حفظ وابستگی بین ویژگیها و پایداری توزیعهای حاشیهای تعادل برقرار کند. این عمل متعادل کننده تحت تأثیر سه پارامتر بودجه کل حریم خصوصی(ε)، تعداد کل تاپلها در پایگاه داده(n) و سودمندی هر توزیع حاشیهای نوفهدار در مرحله دوم(θ) است.
یک توزیع نوفهدار دارای سودمندی θ است اگر نسبت مقیاس اطلاعات به مقیاس متوسط نوفه، کمتر از θ نباشد.
آزمایشات:
بررسی تاثیر تابع F:
F تقریباً در همه موارد به طور قابل توجهی عملکرد بهتری نسبت به I دارد. F به بهبود کیفیت شبکه بیزی ساخته شده توسط PRIVBAYES کمک میکند. برای مقادیر k کوچک (یعنیk=0,1,2 )، زمان صرف شده برای ساخت یک شبکه بیزی با F، کمتر از 1 دقیقه و ناچیز است. برای مقادیر بزرگتر k، زمان صرف شده معمولاً بیشتر است (چند ساعت برای k = 5). نگرانیهای ذکر شده مشکل بزرگی نیست زیرا وظیفه انجام محاسبات روی تابع F برای ترکیبات مختلف ویژگیها، نیازی به انجام آن به صورت بلادرنگ ندارد و میتوان آن را به وظایف کوچکتر تقسیم کرده و به صرت همزمان انجام داد.
انتخاب θ:
تنها پارامتری که PRIVBAYES درنظر میگیرد، درجه شبکه بیزی(K) است که از معیار θ-useful برای انتخاب خودکار مقدار مناسب برای k استفاده میشود. در این آزمایش عملکرد PRIVBAYES با مقادیر متفاوت θ بررسی میشود:
- θ کوچک منجر به توزیعهای حاشیهای با نوفه زیاد در مرحله دوم PRIVBAYES میشود، که مجموعهداده جعلی تولیدی را به شدت متفاوت با دادههای اصلی میکند.
- θ بزرگ ساخت شبکه بیزی با کیفیت بالا در مرحله اول PRIVBAYES را دشوار میکند، که همچنین منجر به دادههای جعلی ضعیف میشود.
مقدار مناسب θ باید در محدوده [2، 16] باشد.
α-way Marginals:
در این بخش PRIVBAYES با رویکردهای لاپلاس، فوریه و Contingency مقایسه میشود. PRIVBAYES عملکرد بهتری نسبت به سایر روشها دارد. برتری PRIVBAYES زمانی آشکارتر میشود که ε کاهش یا α افزایش یابد. برای توضیحات بیشتر، زمانی که ε کوچک است، PrivBayes تصمیم به ساخت شبکه بیزی با درجه بسیار کوچک میگیرد. در نتیجه، توزیعهای حاشیهای در مرحله دوم PRIVBAYES در برابر تزریق نوفه قویتر خواهند بود، که تضمین میکند کیفیت دادههای جعلی به میزان قابلتوجهی کاهش نمییابد. در مقابل، عملکرد لاپلاس و فوریه نسبت به ε بسیار حساس است، به همین دلیل وقتی ε کاهش مییابد دچار خطاهای قابلتوجهی میشوند. Contingency حاشیههای نادرستی را با بودجه حفظ حریم خصوصی کم ایجاد میکند. و عملکرد این روش با افزایش ε به آرامی بهبود مییابد.
با افزایش α، Qα2 به مجموعه بزرگتری از حاشیهها اشاره میکند، در این صورت کوئریهای Qα حساسیت بالاتری دارند. بنابراین، روش لاپلاس برای حفاظت از حریم خصوصی نیاز به تزریق مقدار بیشتری نوفه به Qα دارد که منجر به خطاهای پرس و جو میشود. فوریه نیز از مشکل مشابهی رنج میبرد. PRIVBAYES نسبت به α حساس نیست، زیرا شبکه بیزی به خوبی همبستگیهای بین ویژگیها را ثبت میکند.
Jun Zhang et al. “Privbayes: Private data release via bayesian networks”. In: ACM Transactions on Database Systems (TODS) 42.4 (2017), pp. 1–41.