در سالهای اخیر، انتشار دادهها با حفظ حریم خصوصی آنها توجه زیادی را به خود جلب کرده است. روشهای حریم خصوصی تفاضلی موجود برای زمانی که ابعاد مجموعهداده ورودی، بالا است بدلیل نوفه تزریفی زیاد، افزایش خطاهای آشفتهسازی و پیچیدگی محاسباتی بالا، کارآیی خوبی ندارد. به همین دلیل DPPro معرفی شده است.
DPPro، ابعاد یک مجموعهداده با ابعاد بالا را به کمک تبدیل تصادفی کاهش داده و فاصله نسبی نقاط داده را حفظ کرده و سپس نوفه را به منظور فراهم کردن حریم خصوصی به آن اضافه میکند.
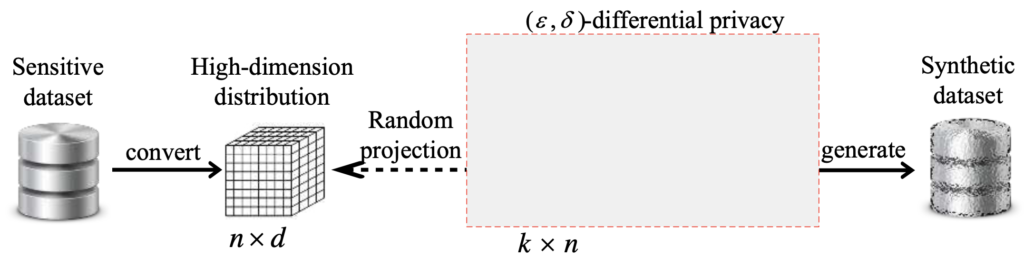
مراحل DPPro:
- انتخاب ماتریس تبدیل R و حساسیت آن: ماتریس انتخابی باید دو مورد زیر را درنظر بگیرد:
- به کمک محاسبه فاصله L2، میزان فواصل بین ویژگیها حفظ و از آن برای گروهبندی کاربران استفاده شود.
- به حداقل رساندن نوفه اضافه شده و به حداکثر رساندن سودمندی.
- انتخاب تضمینهای حریم خصوصی (ε, δ)، که توزیع نوفهها را تعیین میکند.
- تعیین بعد تبدیلی بهینه(K): k بهینه به کمک فرمول زیر بدست میآید:
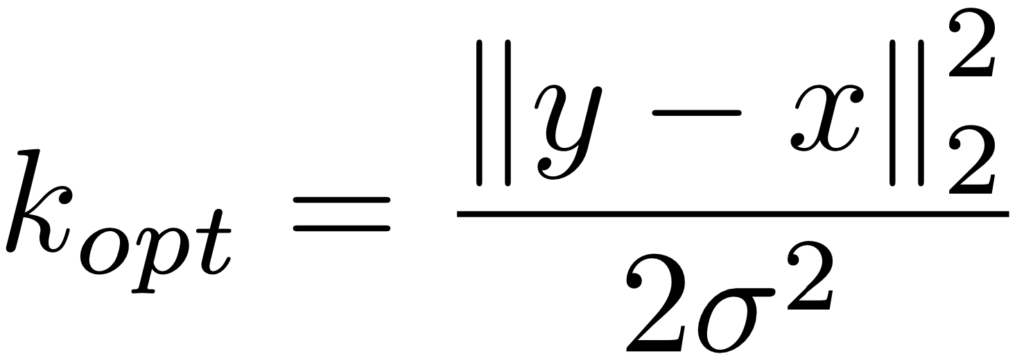
آزمایشات:
در این قسمت عملکرد DPPro با سه روش موجود JTree، PrivBayes و PriView مقایسه میشود. برای بررسی عملکرد طبقهبندی SVM، روش DPPro با PrivateSVM مقایسه میشود.
روشهای ارزیابی: برای ارزیابی عملکرد DPPro، برای هر مجموعهداده، یک مجموعه پرسوجو با ۱۰۰۰۰ پرسوجو خطی تصادفی ایجاد میشود و میانگین فاصله کل تغییرات بین مجموعه دادههای اصلی و مجموعه دادههای نوفهدار گزارش میشود. سودمندی دادههای منتشر شده با میانگین خطای L2 اندازهگیری میشود:
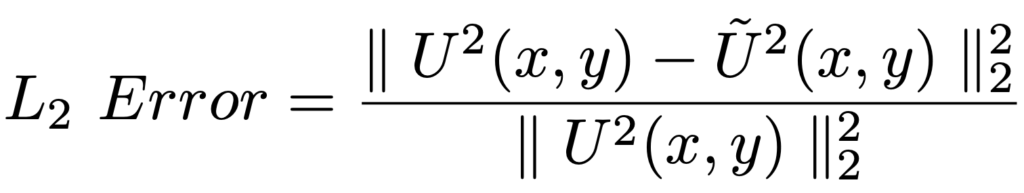
U2(x,y): مجذور فواصل بین دو کاربر در فضای اصلی
U’2(x,y): مجذور فواصل بین دو کاربر در فضای تبدیل شده
هر چه خطای L2 کمتر باشد، سودمندی داده بیشتر است.
بررسی عملکرد DPPro بر روی مجموعهداده باینری: برای اینکار بودجه حریم خصوصی متفاوتی را در نظر میگیریم. در بیشتر حالتها DPPro دقت بهتری نسبت به روشهای JTree و PrivBayes دارد. برتری DPPro برای εهای کوچک آشکارتر است. بنابراین DPPro یک روش معقول برای ایجاد تعادل بین تامین حریم خصوصی و سودمندی داده در مجموعهداده مصنوعی است.
تاثیر ابعاد دادههای تبدیل شده بر DPPro: خطای L2 مربوط به DPPro با افزایش تعداد ابعاد(k)، کاهش مییابد. به این دلیل که برای σ ثابت، خطای L2 مجذور فاصله بین دو کاربر در DPPro با افزایش k، کوچکتر میشود.
بررسی عملکرد DPPro بر روی مجموعهداده غیرباینری: DPPro در بیشتر حالتها بهتر از PrivBayes است. PrivBayes تنها در حالتی از DPPro و JTree بهتر است که ε=0.2 (مجموعهداده TPC-E) اما باز هم در این حالت، عملکرد DPPro بهتر از JTree است.
بررسی عملکرد DPPro بر طبقهبندی SVM: عملکرد DPPro بهتر از PrivBayes و JTree است. سطح حریم خصوصی بالاتر موجب کاهش سودمندی داده میشود. DPPro میتواند سودمندی دادههای منتشر شده را حفظ و حریم خصوصی مناسبی را فراهم کند.
Chugui Xu et al. “DPPro: Differentially private high-dimensional data release via random projection”. In: IEEE Transactions on Information Forensics and Security 12.12 (2017), pp. 3081–3093