امروزه بیشتر تحقیقات انتشار دادهها تحت LDP بر روی دادههای با ابعاد پایین تمرکز کردهاند. دادههای با ابعاد بالا در دنیای واقعی، مانند تشخیصهای پزشکی و دادههای رفتاری، در دادهکاوی و تجزیه و تحلیل به طور گسترده استفاده میشوند. دادههای با ابعاد بالا حاوی اطلاعات حساس کاربری زیادی هستند و زمانی که این دادهها بدون حفاظت مناسب منتشر شوند، منجر به نقض حریم خصوصی کاربران میشود. بنابراین، به دست آوردن نتایج آماری از دادههای با ابعاد بالا با حفظ حریم خصوصی ضروری است. انتشار دادههای با ابعاد بالا از “نفرین ابعاد” رنج میبرند:
- هزینه محاسبات: ویژگیهای زیاد دادههای با ابعاد بالا منجر به توزیع پراکنده در مورد نقاط داده میشود. هزینه محاسبات با توجه به روشهای مختلف آشفتهسازی، به صورت خطی یا نمایی افزایش می یابد. برای کاهش هزینه محاسبات، روشهای موجود با نمونهگیری، ابعاد را کاهش میدهند که به ناچار منجر به کاهش در دسترس بودن دادهها میشود.
- نسبت سیگنال به نوفه: با اضافه کردن نوفه به دادههای با ابعاد بالا، قدرت سیگنال دادههای اصلی کاهش مییابد که منجر به بیاعتباری مقادیر اصلی منتشر شده میشود.
کاهش دامنه، یک راهحل برای غلبه بر مشکلات گفته شده است. روشهای کاهش دامنه:
- کاهش دامنه براساس عدم وابستگی دادهها:
- PriView: فرض میکند که همه ویژگیها به صورت متقابل تحت DP مستقل هستند. این فرض عملی نیست، چراکه منجر به ایجاد تفاوت بین توزیع واقعی و تخمینی میشود.
- کاهش دامنه براساس وابستگیهای موجود بین ویژگیها:
- PrivBayes: همبستگی بین ویژگیها را تحت DP استنباط میکند. دقت این روش با افزایش جفت ویژگیها کاهش مییابد. LoPub بر اساس PrivBayes ایجاد شده است با این تفاوت که تحت LDP است. LoPub سازوکار استنتاج PrivBayes را به ارث برده است، اما پیدا کردن همه همبستگیهای موجود بین ویژگیهای متفاوت غیرممکن است.
- Junction Tree: برای انتشار دادههای با ابعاد بالا مبتنی بر SVT است. از SVT برای پاسخ دادن به دنبالهای از پرسوجوها استفاده میشود. اکثر انواع SVT، DP را تضمین نمیکنند. بنابراین این روش DP را تضمین نمیکند.
برای انتشار دادههای با ابعاد بالا، حفظ همبستگی بین ویژگیها بعد از کاهش دامنه و تضمین LDP اجباری است.
برای حل مشکلات هزینه محاسباتی و در دسترس بودن دادههای منتشر شده با ابعاد بالا تحت LDP، الگوریتم PrivPJ طراحی شده است که شامل ۳ مرحله زیر است:
- تبدیل تحت LDP: کاربر بعد از آشفته کردن دادهها از طریق نمونهبرداری RAPPOR، آنها را به سرور ارسال میکند. برای جلوگیری از هزینه بالای محاسبات ناشی از ارسال چندین آیتم داده، روش نمونهبرداری RAPPOR به کاربران اجازه میدهد تا یک آیتم را به صورت تصادفی انتخاب کنند. این روش در ابتدا از Bloom filter برای تبدیل هر ویژگی به یک رشته بیت استفاده میکند سپس هر بیت به طور تصادفی به کمک RR تبدیل میشوند. درنهایت این رشته بیتهای تصادفی به هم متصل شده و بردار بیتی (d*mj) را تولید میکنند. و سپس به سرور ارسال و سرور نیز داده همه کاربران را جمع کرده و از دادههای آماری به دست آمده برای تخمین توزیع مشترک استفاده میکند.

- تخمین توزیع مشترک: برای اینکار از روش mVAE استفاده میشود. این روش میتواند خطای تقریبی را از توزیع حاشیهای تا توزیع مشترک به حداقل برساند و توزیع احتمال با ابعاد بالا را به طور موثر بدست آورد.

- کاهش ابعاد و تولید مجموعهداده جدید: بر اساس تخمین توزیع مشترک، سرور ابعاد را کاهش داده و مجموعهداده جدید را با محاسبه همبستگی ویژگیها و ساخت junction tree، منتشر میکند. این قسمت شامل مراحل زیر است:
- ساخت شبکه Markov: اطلاعات متقابل (میزان همبستگی) بین دو ویژگی را محاسبه میکند.
- ساخت junction tree:

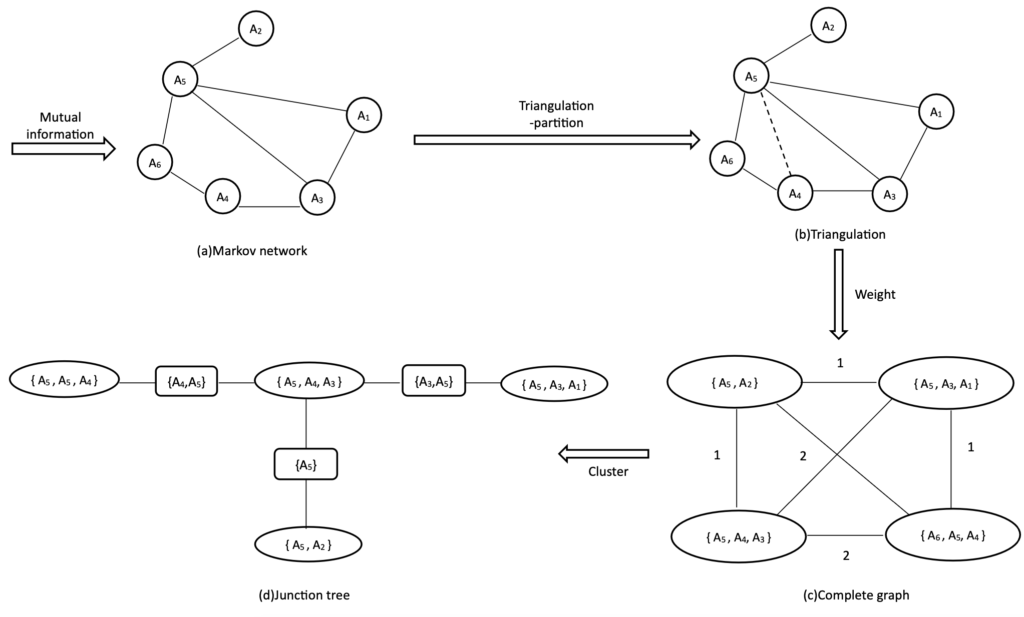
- تولید مجموعهداده جدید: بعد از مشخص شدن ویژگیهای خوشهها به کمک junction tree، سرور مجموعه R را خالی در نظر میگیرد. آنگاه سرور به صورت تصادفی ویژگیها را برای تخمین توزیع مشترک، نمونهبرداری میکند. پس از آن، جداکننده مشترک پیدا میشود. در صورت نمونهبرداری شدن همه ویژگیها، سرور فرآیند را تمام میکند. درنهایت، در مجموعهداده جعلی، P(A) توزیع مشترک A است که به صورت زیر محاسبه میشود:
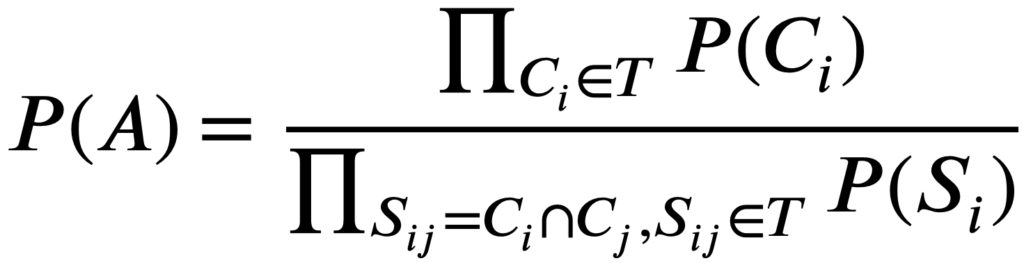
درنهایت سرور دادههای ارسالی از کاربران را جمعآوری کرده و به کمک الگوریتم ۴، فراوانی و میانگین را تخمین میزند:

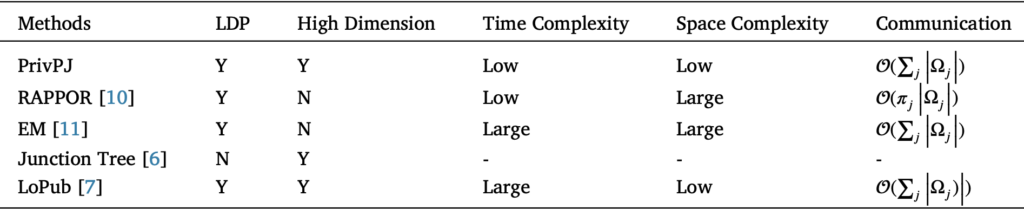
جدول زیر مقایسه بین روشهای موجود و روش privPJ را نشان میدهد:
Hua Zhang et al. “Publishing locally private high-dimensional synthetic data efficiently”. In: Information Sciences 633 (2023), pp. 343–356