کاوش مجموعه آیتمهای مکرر (frequent itemset mining) به دلیل کاربردهای عملی فراوان، مورد توجه بسیاری از پژوهشگران قرار گرفته است. اما برای شناسایی مجموعه آیتمهای مکرر، کاربران میبایست دادههای خود را افشا کرده که میتواند منجر به نشت حریم خصوصی ایشان گردد. از سویی دیگر، حریم خصوصی تفاضلی به عنوان مدلی استاندارد برای حفظ حریم خصوصی مورد توجه و کاربرد بسیار قرار گرفته است. اما در حریم خصوصی تفاضلی، میبایست جمع کننده داده مورد اعتماد باشد که به دلیل غیر عملیاتی بودن آن، مفهوم حریم خصوصی تفاضلی محلی مطرح شده است، به طوری که در آن مکانیزمهای حفظ حریم خصوصی تفاضلی دادهها پیش از رسیدن به جمع کننده داده و توسط خود کاربر، اعمال میشوند. روشهای متعددی برای پیادهسازی حریم خصوصی تفاضلی محلی روی کاوش مجموعه آیتمهای مکرر پیشنهاد شده است که مهترین نقطه ضعف آنها در نظر نگرفتن همبستگی میان داده و نیز سودمندی پایین به دلیل افزایش نویز میباشد. مقاله حاضر در تلاش است راهحلی ارائه نماید که محدودیتهای روشهای پیشین را از برده و سودمندی مکانیزم حفظ حریم خصوصی را به میزان قابل توجهی افزایش دهد.
بخش کلیدی در روش پیشنهادی این مقاله، تکنیک تصادفیسازی دو مرحلهای برای پیادهسازی حریم خصوصی تفاضلی است. تکنیک پیشنهاد شده همبستگی میان آیتمهای موجود در مجوعه آیتمهای کاربر را شناسایی و تا حد امکان از آن برای حفظ حریم خصوصی در محدوده معینی استفاده میکند.
در این مقاله مدل ساختاری یک سیستم چند مرحلهای پیشنهاد شده است. در این مدل، کاربر اطلاعات آشفته(اطلاعات به همراه نویز) خود را در m مرحله به جمعکننده داده ارسال میکند. مدل پیشنهادی از سه مرحله اصلی تشکیل شده است:
در مرحله اول هر کاربر اطلاعات آیتمهای حساس خود را به صورت آشفته به جمعکننده داده ارسال میکند. سپس جمعکننده داده اطلاعات دریافتی از تمام کاربران را جمع کرده و مجموعه آیتمهای مکرر۱ را تخمین میزند. در نهایت مجموعه تخمین زده شده به تمام کاربران ارسال میشود.
در مراحل j ام(بعد از مرحله اول و پیش از مرحله آخر)، کاربران با کمک آیتمهای حساس خود و نیز مجموعه آیتم مکرر که در مرحله j-1 به دست آوردهاند، مجموعه آیتمهای jام کاندید(1<j<m) را تولید میکنند. سپس هر کاربر اطلاعات آشفته و کدگذاری شده مجموعه آیتمهای jام محاسبه شده را به جمعکننده داده ارسال میکند. نهایتا جمع کننده داده مجموعه آیتمهای مکرر jام را تولید و مجدد به کاربران ارسال میکند.
در مرحله پایانی، هر کاربر از روی مجموعه آیتمهای مکرر تخمین زده شده در مرحله قبل، مجموعه آیتمهای jام کاندید را تولید میکند به طوری که j=m,m+1,…,k است و مقدار k برابر اندازه بزرگترین مجموعه کاندید تولید شده پیشین است. سپس هر کاربر اطلاعات آشفته کدگذاری شده درباره تمام مجموعه آیتمهای jام کاندید تولید شده را به جمعکننده داده ارسال میکند. جمعکننده داده نیز مجموعه آیتمهای مکرر jام را تخمین زده و تمام مجموعه آیتمهای مکرر تخمین زده شده را منتشر میکند.
تصویر زیر نمایش دهنده مراحل مدل پیشنهادی است.
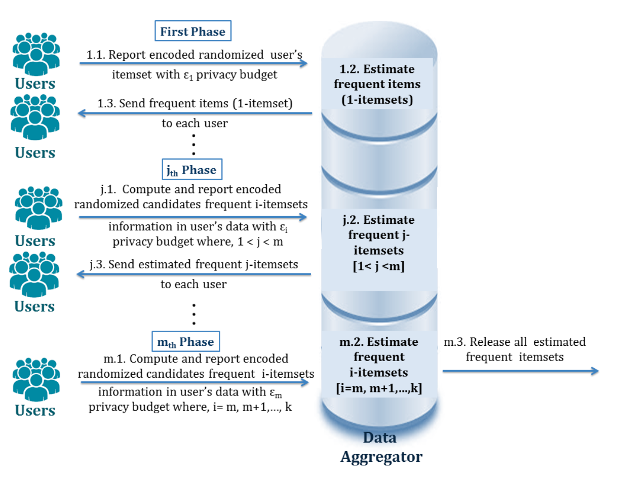
الگوریتمی در این مقاله برای پیادهسازی ساختار پیشنهادی ارائه شده است که از سه بخش اصلی کدگذاری داده و تصادفیسازی در بخش کاربر و تخمین مجموعه أیتمهای مکرر در بخش جمعکننده داده تشکیل شده که تشریح هر بخش در مقاله به صورت خلاصه ذکر شده است.
همچنین چهار مجموعه داده برای پیادهسازی الگوریتم و مدل پیشنهادی مورد استفاده قرار گرفته است. نتایج به دست آمده از پیادهسازی مدل بر روی یکی از این مجموعه دادهها نشاندهنده ۲.۲ برابر دقت و کارایی بیشتر نسبت به روش پیشنهادی پیشین در این حوزه است. همچنین نتایج حاصل نشان میدهند که با افزایش حجم داده، زمان لازم برای انجام محاسبات افزایش یافته است. از این رو مدل پیشنهادی در این مقاله میتواند کارایی خوبی برای دادههای با حجم پایین داشته باشد.
Sharmin Afrose, Tanzima Hashem, and Mohammed Eunus Ali. 2021. Frequent Itemsets Mining with a Guaranteed Local Differential Privacy in Small Datasets. 33rd International Conference on Scientific and Statistical Database Management. Association for Computing Machinery, New York, NY, USA, 232–236
سلام وقتتون بخیر.امکانش هست این مقاله را برای ینده هم ارسال کنید؟متاسفانه قابل دسترسی نیست.با تشکر
با سلام
به آدرس ایمیلتان ارسال شد.
با آرزوی موفقیت