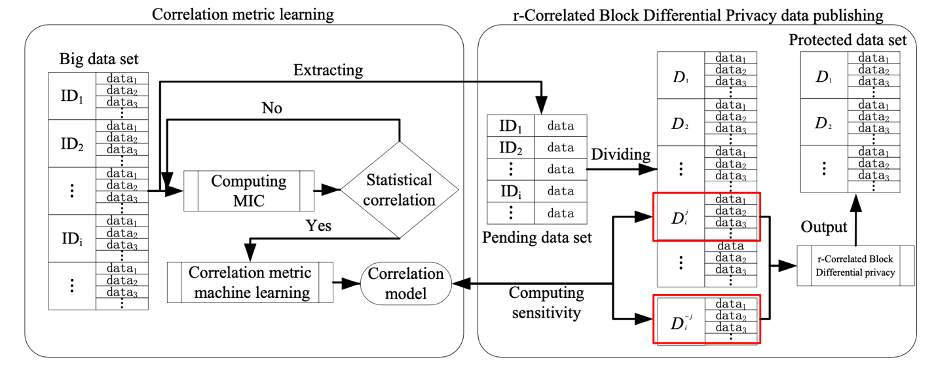
در محیط کلان دادهها، دامنه وسیعی از همبستگی درونی و بیرونی در مجموعههای داد برقرار است که باعث میشود روشهای سنتی حریم خصوصی تفاضلی با شکست مواجه شوند. برای حل این مشکل، مقاله حاضر مدل حفظ حریم خصوصی تفاضلی با نام r- correlated block differential privacy را برای همبستگی درونی دادهها و نیز الگوریتم پیادهسازی آن را پیشنهاد داده است.
الگوریتم پیشنهاد شده در این مقاله، از سه بخش اصلی تشکیل شده است:
بخش اول، استفاده از یادگیری ماشین برای یافتن مدل همبستگی میان دادهها که با استفاده از تحلیل رگرسیون الگوریتم یادگیری ماشین قابل دستیابی میباشد. در این بخش از الگوریتم BP شبکه عصبی برای تمرین مجموعه نمونه استفاده شده است.
بخش دوم که وظیفه اصلی آن محاسبه بلاکهای داده در مجموعه کلان داده است که با الگوریتم کلاسترینگ پیاده سازی شده است. این مرحله با کمک مدل به دست آمده در مرحله قبل که همبستگی میان دادهها را تعیین میکرد، پیادهسازی میشود. بلاکهای ایجاد شده در این مرحله به گونهای است که اجتماع آنها تشکیل دهنده تمام مجموعه کلان داده است و نیز هریک از بلاکها هیچگونه همبستگی با یکدیگر ندارند. لازم به ذکر است که دادههای درون هریک از بلاکها میتوانند با یکدیگر همبستگی داشته باشند.
بخش سوم حساسیت تابع پرس و جو برای هریک از بلاکها را مشخص میکند. برای افزایش میزان دقت حساسیت تابع پرس و جو، از maximum information coefficient (MIC) استفاده شده است.
همچنین در این مقاله مکانیزم پیادهسازی لاپلاس جدید برای اضافه کردن نویز در حریم خصوصی تفاضلی با هدف افزایش دقت در دادههای همبسته ارائه شده است.
تصویر زیر نمایش دهنده مدل پیشنهادی برای حفظ حریم خصوصی تفاضلی در کلاندادهها با وجود دادههای همبسته درونی میباشد.
D. Lv and S. Zhu, “Correlated Differential Privacy Protection for Big Data,” 2018 IEEE 32nd International Conference on Advanced Information Networking and Applications (AINA), 2018, pp. 1011-1018, doi: 10.1109/AINA.2018.00147.