در بخشهای قبلی به بررسی حریم خصوصی تفاضلی (حریم خصوصی تفاضلی سراسری) پرداختیم. در این بخش با مطرح کردن چالشی اساسی در استفاده از حریم خصوصی تفاضلی سراسری، به معرفی حریم خصوصی تفاضلی محلی خواهیم پرداخت.
با افزایش حجم دادههای جمعآوری شده توسط سرپرستهای داده، نگرانیها از نحوه استفاده از این دادهها افزایش یافته است. به همین دلیل تولیدکنندگان داده نمیتوانند به تمامی سرپرستهای داده اعتماد کنند. از همین جهت نیاز دارند تا دادههای خود را به صورت حافظ حریم خصوصی منتشر کنند. برای حل این مسئله، حریم خصوصی تفاضلی محلی [1] معرفی شده است.
همانطور که در شکل زیر نشان داده شده است، در حریم خصوصی تفاضلی، پس از تولید دادهها توسط تولیدکنندگان داده، ابتدا به هر کدام به صورت جداگانه نوفه مطلوب اضافه میشود و سپس برای سرپرستداده ارسال میشود. سرپرستداده میتواند این دادهها را منتشر کند یا هرگونه تحلیل را روی آن انجام دهد. تضمین میشود که خروجی این عملیاتها حافظ حریم خصوصی تفاضلی میباشد.
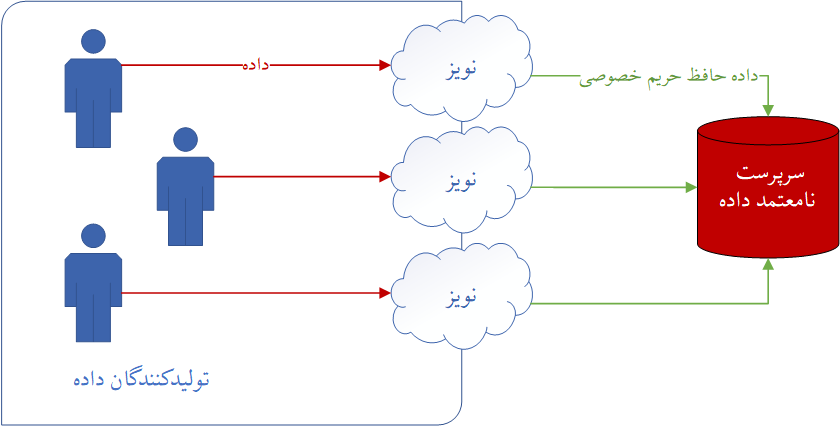
در استفاده از حریم خصوصی تفاضلی محلی، اگر تعداد تولیدکنندگان داده زیاد باشد، نوفه اضافه شده به دادههای دریافت شده توسط سرپرست داده زیاد بوده و برای کنترل این مسئله معمولا مقدار بودجه حریم خصوصی تفاضلی عددی بزرگ در نظر گرفته میشود.
تعریف حریم خصوصی تفاضلی محلی
سازوکار تصادفی \(M: X \rightarrow Z\) حافظ حریم خصوصی تفاضلی محلی با عامل ε میباشد اگر به ازای هر دو جفت مقدار \(x, x’ \in X\) و هر زیرمجموعه از خروجی \(S \subseteq Z\)، داشته باشیم:
\(Pr[M(x) \in S] \leq exp(\varepsilon) . Pr[M(x’) \in S] + \delta\)این تعریف بیان میکند که دادههای تولیدشده توسط دو عضو، پس از افزودن نوفه دارای اختلاف بسیار ناچیز باشد. در حریم خصوصی تفاضلی و در محیطهای مختلف میتوان سازوکارهای مختلفی را استفاده نمود. در بخشهای به معرفی چند سازوکار خواهیم پرداخت.
[1] Kasiviswanathan, Shiva Prasad, et al. “What can we learn privately?.” SIAM Journal on Computing 40.3 (2011): 793-826.